
Executive Summary
When software development infrastructure is treated as an after‑thought, the cracks show fast. As a startup racing to find the product‑market fit, the quality of the foundation for developing the product can be shaped to be flexible and scalable, or cause spectacularly bad outcomes down the line.
What are the typical problems that often go unseen? Let’s picture a nightmare scenario that’s sadly far too common. Engineers lose hours each week wrestling with flaky local environments, undocumented build scripts, and hand‑rolled deployment checklists. If no one “owns” the pipeline, coding standards and dependency versions drift, eroding code clarity and forcing newcomers to reverse‑engineer tribal knowledge before they can ship a single line. Production parity is poor, so bugs hide until late QA cycles or, worse, until customers find them in‑app.
Ever witnessed a release that triggers a confusing scramble? It usually goes like this: designers wait for back‑end fixes, QA blocks on staging access, and product managers juggle ever‑slipping dates. The net result is a culture of “big‑bang” weekend deployments, brittle hot‑fixes, and a mounting fear of touching legacy code. Customer‑support teams feel the pain too; without structured logs or consistent observability, they must ping engineers for every incident, lengthening resolution times and denting customer trust. From a business perspective, lead time stretches from hours to days, and we’re not yet touching cloud bills which can’t be budgeted in advance. Finally, leadership can’t predict when new revenue‑driving features will actually land.
Consequently, teams burn out, team leads quietly give up, and CTOs just accept chaos as the cost of being in the business of software development. But it doesn’t have to be that way.
Treating infrastructure as a product flips this dynamic. By assigning clear ownership, setting success metrics, and building feedback loops, startups turn the release pipeline into a catalyst rather than a cost center. Developers gain confidence to refactor boldly, QA focuses on exploratory tests instead of manual regression, support teams self‑serve diagnostics, and executives see faster, cheaper, more reliable delivery of customer value.
Below is how the full post unpacks this argument:
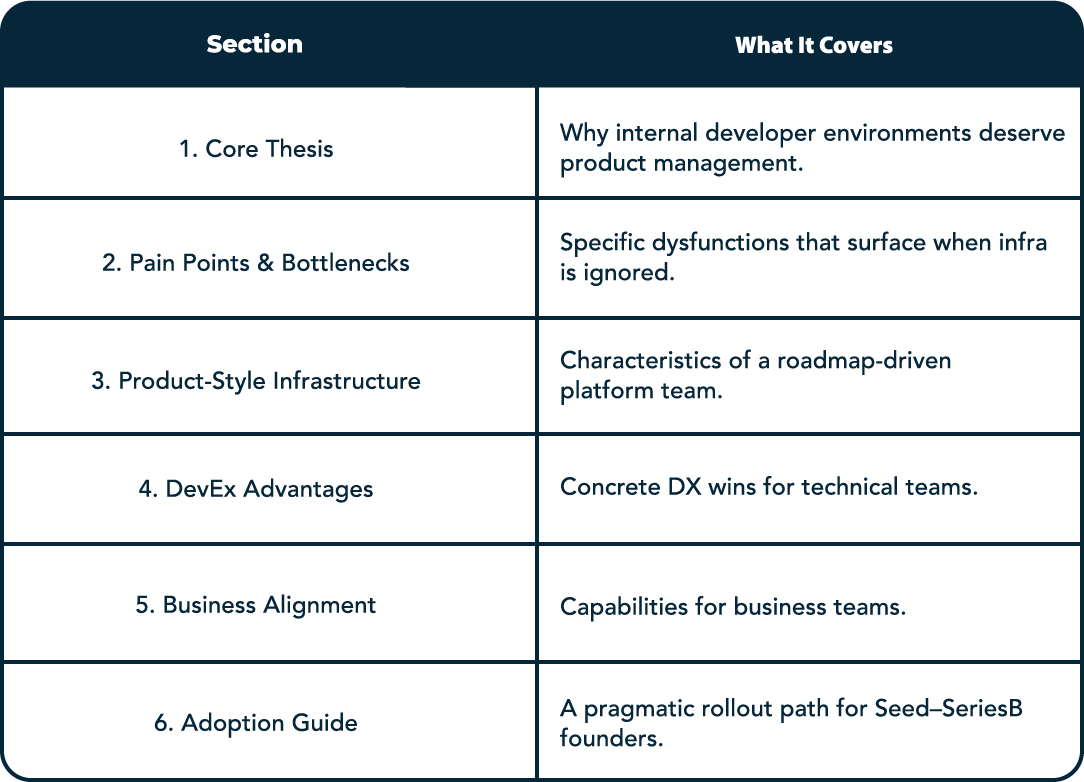
1. Why Infrastructure Belongs on the Product Roadmap
At its heart, software‐development infrastructure is simply a product with a captive user base: your own engineers, testers, designers, data scientists, and customer‑support analysts. They “use” the build pipeline, cloud stack, observability tools, and internal libraries dozens of times every day to create value for your paying customers. When that internal product is neglected, the friction compounds exactly as it would for an external customer: adoption drops, workarounds proliferate, and trust erodes. Early‑stage companies cannot afford that hidden tax.
What are your internal customers' product needs?
1.1 Internal Users, External Stakes
- Engineers need fast feedback loops and deterministic environments to preserve code clarity and technical courage.
- QA and Designers depend on reliable preview builds to validate features without shepherding tickets across siloed backlogs.
- Customer Support staff require structured logs, links to feature flags, and clear error states so they can help external end users.
- Business leaders care about speed, price, and scalability, each of which is directly throttled or enabled by infrastructure quality.
When these internal customers are forced onto brittle tooling, the cost shows up as recruitment churn, missed market windows, and ballooning spend. Conversely, a product‑grade platform becomes a force multiplier: hiring ramps faster, features ship sooner, and the company can test new business bets reliably and without new excess costs.
1.2 Applying Product‑Management Discipline
Here are a few guidelines you can lean on when establishing business processes for a healthy internal developer environment.
- Clear Problem Statements – Treat recurring friction (e.g., “staging is always broken on Mondays”) as you would a user‑reported bug. Define it, size it, and decide whether solving it advances your strategy.
- User Research & Feedback Loops – Conduct lightweight surveys or “DX office hours” to surface pain points before they become outages. Just as you measure Net Promoter Score for customers, track an internal “Developer Satisfaction” metric.
- Roadmap & Prioritisation – Allocate deliberate budget—time, headcount, and cloud credits—so infrastructure work is not squeezed only into weekend heroics. Rank backlog items against business OKRs: shorter lead time, lower unit cost, higher release velocity.
- Success Metrics – Adopt DORA indicators (deployment frequency, lead time, change‑failure rate, MTTR) and publish them company‑wide. Metrics shift the conversation from anecdotal pain to measurable progress.
- Versioning & Change Management – Release internal libraries with semantic versions, automated changelogs, and deprecation guides. Engineers gain the same predictability they offer external customers.
Dedicated Ownership – Even at Seed stage, an “infra champion” with 20–30 % of their bandwidth can own the vision, curate the backlog, and coordinate rollouts. By Series B, a small platform squad returns outsized leverage compared with hiring more feature developers.
1.3 Strategic Payoff
If you’re still wondering why you should go to all the trouble of what may seem like doubling your product work, here are a few benefits of that investment that you may find worthwhile.
- Faster Iteration – Teams experiment safely; a new pricing flow or machine‑learning model can be deployed behind a flag in hours, not days.
- Lower Coordination Overhead – Autonomous pipelines mean designers tweak UI copy and QA runs smoke tests without blocking back‑end merges.
- Higher Code Quality – Standardised templates, enforced linting, and one‑click environment provisioning let engineers refactor fearlessly, shrinking tech debt rather than compounding it.
- Resilience & Confidence – Telemetry, automated rollbacks, and canary deploys curb late‑night incidents and protect brand trust.
- Capital Efficiency – Smart autoscaling, shared service meshes, and sane default configurations cut cloud waste, often a top‑three expense line at growth‑stage startups.
In short, infrastructure becomes the chassis on which every product experiment rides. By treating it as a product—owned, measured, and iterated—you transform a potential drag into a flywheel that powers speed, reliability, and sustainable scale.
2. Infrastructure Pain Points & Bottlenecks in Typical Early‑Stage Setups
In the scramble to ship an MVP, most young companies treat infrastructure the way homeowners treat wiring: something to bury behind drywall and forget. That choice feels rational when the backlog is bursting with features and every investor update hinges on “time‑to‑launch.”
Yet the unseen system that stitches code, environments, and releases together quietly shapes how fast—and how safely—those features can reach users. What begins as a series of quick scripts and manual checklists soon hardens into a maze of one‑off conventions, accessible only to the first engineer who wrote them. When that engineer goes on vacation (or joins another startup), momentum stalls and the remaining team is left decoding arcane build flags instead of building products.
The pain shows up first as small paper‑cuts: a tests folder that takes ten minutes to run, a staging database that drifts from production, a missing environment variable that breaks only on a Tuesday deployment. Each incident is minor, but together they create a tax on every ticket. Engineers hesitate to refactor because they can’t predict side‑effects; product managers slip deadlines to appease QA; customer support can’t self‑diagnose a bug without paging the on‑call developer. The company’s culture quietly shifts from “move fast” to “move carefully,” then finally to “move only when absolutely necessary.”
These recurring frustrations cluster around a handful of systemic weak points. By naming those weak points we can measure, prioritize, and ultimately fix them. The table that follows categorizes the most common pain points we see in Seed‑to‑Series B companies, along with the business impact that each one inflicts.
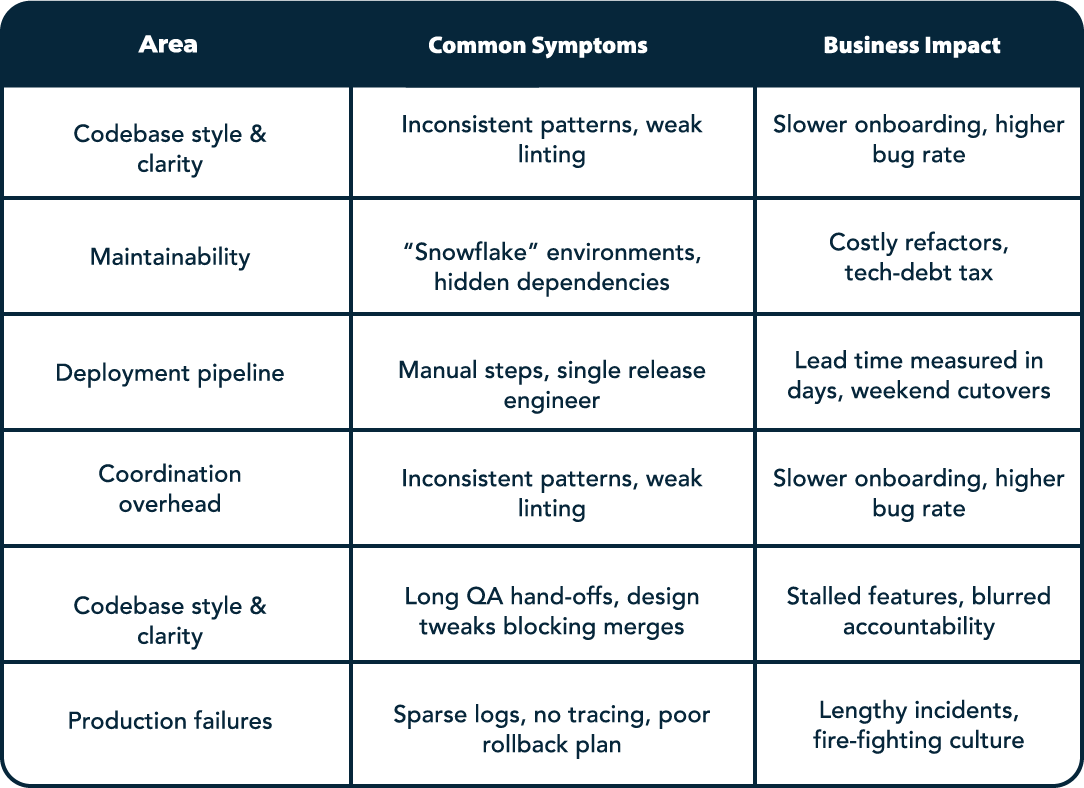
3. Product‑Style Infrastructure: What Does It Look Like?
Picture the internal developer environment you give your engineers as if it were a subscription app you sell to paying customers. If the experience is slow, confusing, or unpredictable, users churn; if it is fast, intuitive, and reliable, they stay longer and do more. That same consumer‑grade mindset, clear positioning, measured outcomes, regular releases, and tight feedback loops, is what separates a product‑style infrastructure from a loose collection of scripts.
Let’s dive into the details of what that product approach looks like.
3.1 Clear Problem Statements & KPIs
Every initiative starts with a plainly written problem: “Staging environments drift from production, causing 30 % of release rollbacks.” From there, you pick one or two measurable outcomes. For example, shrinking lead time from merge to production to under three hours, or cutting change‑failure rate below 5 %. These become your North Star metrics, broadcast on the same dashboard that tracks customer growth or burn rate, so the whole company sees infrastructure progress in business terms.
3.2 Dedicated Ownership & Backlog
Even a five‑person engineering team benefits from an infra champion—someone who guards the vision, curates the backlog, and says “no” to work that doesn’t advance the roadmap. At the Seed stage, that might be a rotating hat; by Series B, you’re better off with a small platform squad. All incoming requests—“add Redis,” “support feature flags,” “speed up tests”—land in a single, visible backlog that is triaged just like customer features. Engineers know where to propose improvements and can see why a ticket is in or out of scope for the next sprint.
3.3 User Research for Internal Customers
Treat developers, QA, designers, and support agents as segmented personas. Run quarterly DX surveys that ask: How long does it take to set up a new service? Which step in the pipeline causes the most friction? Follow up with short interviews or “office hours” to observe how people actually use the tools. Insights feed directly into your backlog, preventing architecture decisions from being made in a vacuum.
3.4 Release Cadence, Versioning, and Communication
A product‑grade platform never ships giant, unpredictable drops. Instead, it moves in incremental, reversible steps: pull requests that pass automated tests, then roll out behind canary deployments or feature flags. Internal libraries follow semantic versioning with automated changelogs so engineers know exactly what changed and whether a bump is breaking. Weekly or bi‑weekly “infra release notes” in Slack keep everyone informed and reinforce the idea that tooling evolves just like the customer‑facing app.
3.5 Self‑Service Interfaces
The fastest way to remove coordination overhead is to let teams help themselves. A one‑click environment generator spins up a fully configured sandbox in minutes; a command‑line template scaffolds a new microservice with logging, metrics, and CI pre‑wired. These interfaces are documented, discoverable, and governed by sensible defaults so new hires can push code on day one without memorizing tribal knowledge.
3.6 Feedback Loops & Continuous Improvement
Metrics alone are not feedback; people need tight loops. Pipeline failures post automatically to a shared channel with a link to the exact failing step. Support tickets are tagged with stack traces that tie back to a service and a commit. Monthly retros pull data from DORA dashboards—lead time, deployment frequency, MTTR—to spotlight regressions and celebrate wins. Crucially, fixes and enhancements are shipped quickly, reinforcing that user feedback leads to visible change.
3.7 Security, Cost, and Compliance as First‑Class Concerns
A mature product accounts for trust and economics. Templates come with least‑privilege IAM roles; container images are scanned on every push; cost dashboards alert when a service exceeds its budget envelope. By baking these guard‑rails into the platform, you avoid reactive “security weeks” or surprise cloud bills that derail the roadmap.
Summarizing Product‑Style Infrastructure
In essence, a product‑style infrastructure behaves like a well‑run SaaS offering: it has a roadmap, a budget, regular releases, clear success metrics, named owners, observable user behaviour, and a relentless focus on reducing friction. When early‑stage startups adopt this posture, they turn infrastructure from a hidden liability into a visible asset, one that compounds engineering velocity, safeguards reliability, and scales in lock‑step with customer demand.
4. Developer Experience Focus: Advantages
Developer Experience isn’t about perks; it’s about the flow of work. The payoff shows up in plain business KPIs: faster cycle times, fewer defects, and predictable delivery. For Seed–Series B companies—where every engineer is effectively “full‑stack plus ops”—good DX is leverage. It lets a small team ship like a larger one without ballooning headcount or process.
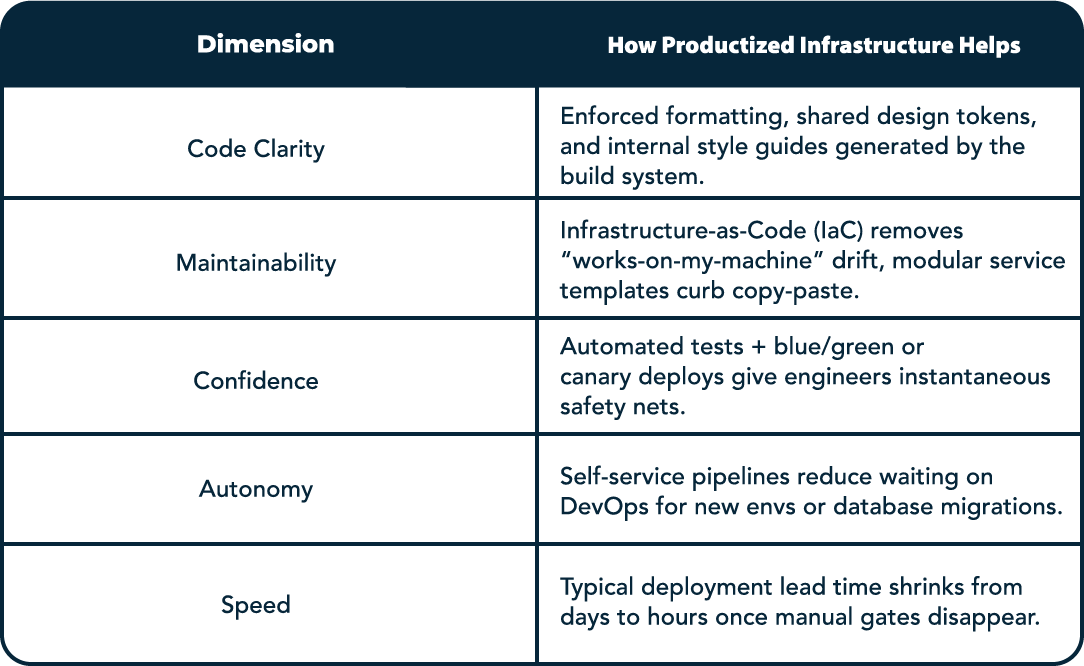
Three themes matter most to teams on the ground.
— First, code clarity: consistent templates, enforced style guides, and shared components reduce variability.
— Second, maintainability: Infrastructure‑as‑Code, versioned internal libraries, and standard service scaffolds keep the system from drifting.
— Third, confidence: reliable tests, fast CI, canary/feature flags, and one‑click rollbacks give engineers psychological safety.
DX also cuts coordination overhead. Self‑service environments and preview builds mean designers can verify UI changes and QA can run regressions without blocking backend merges. Customer Support can reproduce issues using structured logs and trace links to features. These patterns shrink deployment lead time from days to hours, reduce cross‑team dependencies, and make production failures both less frequent and simpler to debug.
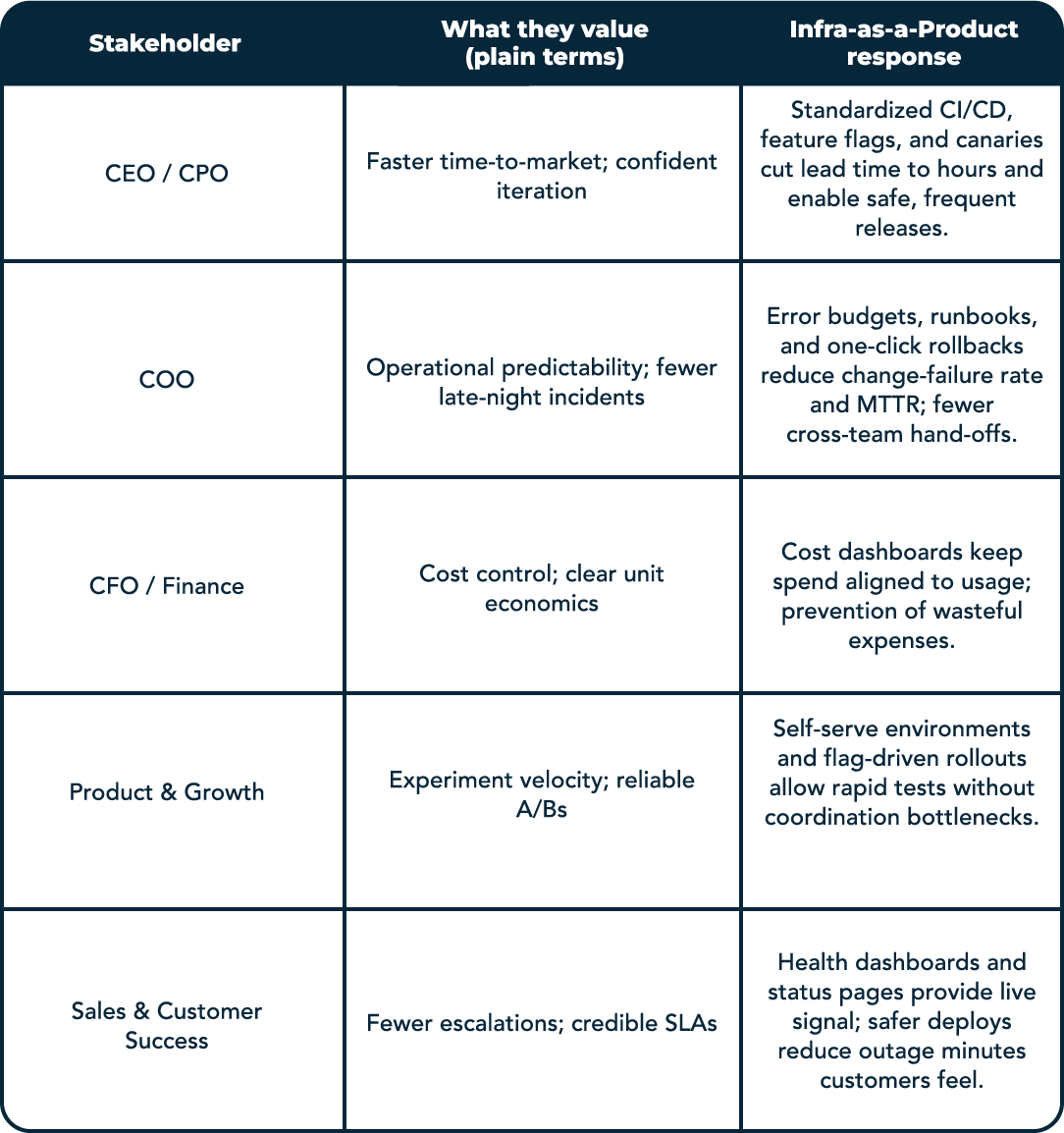
5. Meeting Business Stakeholders Where They Are
Early‑stage companies win by turning infrastructure into language the business already speaks: speed, price, and scale. A product‑style platform shortens deployment lead time from days to hours, reduces the number of people needed to ship, and lowers the risk of each change. That gives the CEO a faster path to market, the CFO cleaner cost curves, and the COO fewer fire drills. Just as importantly, it makes outcomes predictable: lead times, failure rates, and recovery times become measurable and improvable, rather than mere estimates.
Customer‑facing teams feel the impact immediately. When observability, feature flags, and reliable rollbacks are baked in, production failures are both less frequent and easier to debug. Support can reproduce issues with a link to a trace, pull the right logs without paging engineering, and, when needed, toggle a flag or trigger a safe rollback. Time‑to‑resolution drops, ticket escalations shrink, and customer trust rises.
For Seed–Series B founders, the move is pragmatic: start with a self‑service pipeline, preview environments, baseline logging/tracing, and feature flags. Publish simple DORA dashboards so leadership sees progress in business terms. The table below maps core stakeholders to what they value, and how “infra as a product” meets that need.
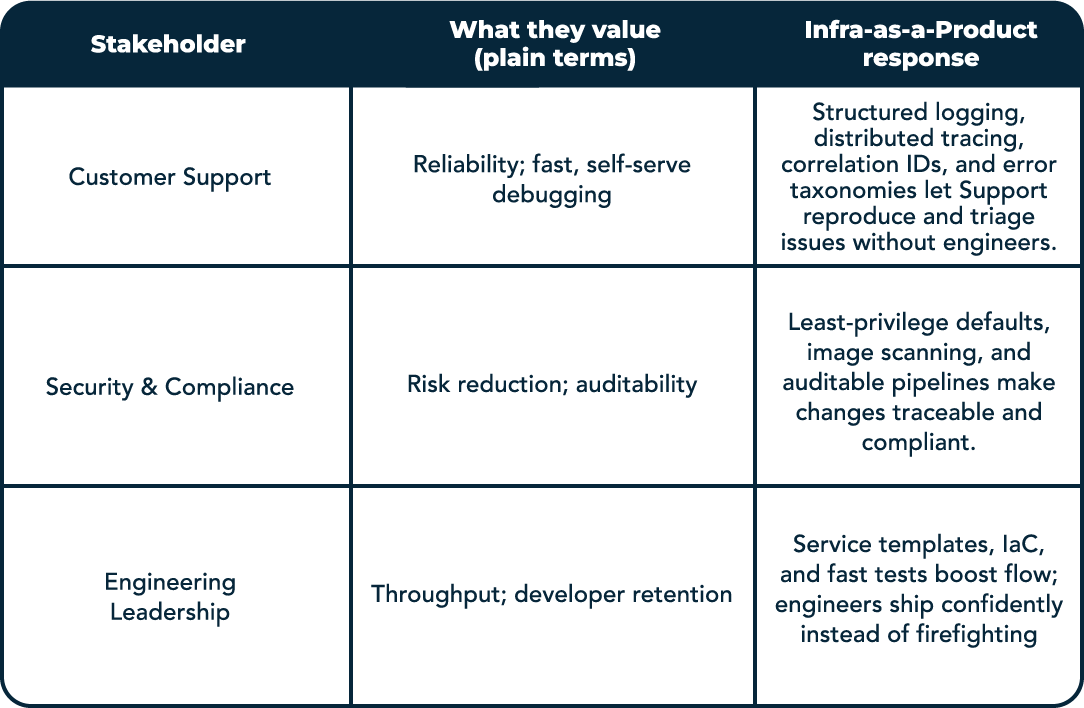
With all these benefits visible, it is much easier to “sell” the vision for infrastructure-as-a-product, should you decide to champion it.
6. Adoption Guide for Seed–Series B Startups
If you choose to go the route of infrastructure-as-a-product, treat this like any other product rollout: define the problem, assign an owner, ship quick wins, and iterate with metrics. The goal is a paved road that most teams will happily take because it’s faster and safer than the side streets.
6.1 Name an owner and the outcomes (Week 0–1)
Appoint a Platform Champion (an experienced engineer or EM with 20–30% capacity at Seed; a small platform squad by Series B). Publish 3–4 outcomes tied to business goals: “Cut lead time from days to hours,” “Increase deployment frequency,” “Reduce change‑failure rate,” “Halve MTTR.” Define how you’ll measure them (DORA dashboard, simple cost report, developer satisfaction pulse). This turns infrastructure from a cost center into a line item with ROI.
6.2 Baseline reality and map friction (Week 1–2).
Run a 90‑minute “DX retro” across engineering, QA, and Support. Ask: Where do releases slow down? Which steps break most often? What can’t Support see in incidents? Capture the top ten pains and time costs (e.g., “new service setup = 1 day,” “rollback = manual, 45 minutes,” “staging drifts weekly”). This becomes your backlog, sized in hours saved and risk removed—not just technical elegance.
6.3 Ship quick wins that move metrics (Week 2–4).
Target changes that reduce coordination and increase confidence immediately:
- CI sanity pass: enforce basic tests and formatting on every PR; fail fast with clear messages.
- Feature flags + canary deploys: make safe, partial rollouts the default.
- One‑click rollbacks: turn scary deploys into reversible actions.
- Structured logging: add correlation IDs so Support can follow a request across services.
- Service template: scaffold for a new service with logging, metrics, health checks, and CI pre‑wired.
Each win should be visible (release notes in Slack) and linked to the outcomes you set.
6.4 Build the paved road (Month 2)
Standardize the golden path for building and shipping:
- Self‑service environments: preview/staging created via a script or button, with production‑like config.
- Infra‑as‑Code: capture environments in code to eliminate “works on my machine.”
- Semantic versioning + changelogs for internal libraries, so upgrades are predictable.
- Guardrails by default: least‑privilege access, image scanning, and budgets built into templates.
The rule of thumb: if two teams did the same task differently last month, give them a shared, simpler default this month.
6.5 Wire in observability and support workflows (Month 2)
Treat Support as a first‑class user. Provide:
- Dashboards that show service health and recent changes.
- Trace links from user tickets to logs and the offending commit.
- Runbooks for common incidents with a “safe actions” section (toggle a flag, trigger a rollback).
This alone shortens time‑to‑resolution and reduces escalations that pull engineers off roadmap work.
6.6 Formalize feedback loops and governance (Month 3)
Publish a short Platform Playbook: what the paved road includes, how to request changes, and when exceptions are allowed. Hold monthly 30‑minute DX office hours to triage feedback and prioritize. Keep the bar low for suggestions and high for deviations. The message: you can take any path you want, but the paved one is faster, safer, and well‑supported.
6.7 Measure, market, and iterate (ongoing)
Show the business the before/after: deployment frequency up, lead time down, fewer incidents, shorter MTTR, lower cloud waste. Send infrastructure release notes with a plain‑English summary (“Rollback is now one click; average deploy time dropped from 40 to 12 minutes”). Treat adoption as a product problem—celebrate teams using the paved road, spotlight the time they saved, and fold remaining pain points into the backlog.
Additional Considerations
Adopt this stepwise, keep score, and communicate like a product team. You’ll convert infrastructure from background plumbing into a visible engine that accelerates delivery, reduces risk, and scales with the business.
Staffing and budget guidance
- Seed: 0.2–0.5 FTE “platform hat” plus 1–2 days/month from Security/Finance for guardrails and cost reports. Focus on CI, flags, rollbacks, and a basic template.
- Series A: 1–2 FTE platform squad. Add preview environments, IaC, observability, and cost controls.
- Series B: 3–5 FTE platform team with a light product manager role. Mature the golden path, multi‑region readiness, and SLO/error budgets.
Anti‑patterns to avoid
- Big‑bang platform rewrites. Replace the roughest parts first; keep shipping features.
- Tool sprawl. Prefer opinionated defaults over a menu of equivalent choices.
- Hidden work. If it’s not on a roadmap with metrics, it won’t be funded—or trusted.
- Security/compliance as an afterthought. Bake guardrails into templates, not post‑hoc audits.
What “good” looks like within 90 days
- Lead time: days → hours; deployments: weekly → daily (or more).
- Rollbacks: manual → one click; incidents: fewer and shorter with clear runbooks.
- Support: self‑serve reproduction via logs/traces; fewer escalations.
- Teams: choose the paved road because it’s faster, not because it’s mandated.
7. Instead of a Conclusion
By treating infrastructure as a product complete with a roadmap, metrics, and a user‑centred mindset, early‑stage companies unlock faster shipping, happier engineers, smoother support, and more predictable costs. The plumbing stops leaking and starts propelling the whole business forward.
Good luck!







